本投稿は TECOTEC Advent Calendar 2020 の23日目の記事です。
こんにちは。
投資戦略システム事業部の石倉です。
皆さん米株の取引はしてますか?
私も少し前から流行に乗って始めて見ました。
毎晩 「米株 テンバガー 銘柄」と意味のない検索をして寝不足です。
最近米国の株価情報を調べている中で使いやすそうなサイトを見つけたので株価取得方法から簡単な予測までを紹介できればと思います。
とりあえず精度には着目せずに一通りやっていきます。
目次
環境
mac book air
- Catalina 10.15.7
Anaconda
- conda: 4.8.5
- Python: 3.7
使用データ
Alpha Vantageという米国株価を提供しているサイトに登録してapi_keyを取得し、日足データとテクニカル指標のAPIを叩きます。
私は3000円課金してますが、おそらく無料でも使用できるはず...
www.alphavantage.co
環境構築
みんな大好きAnacondaを使って処理を書いていきたいと思います。
使用するライブラリは以下の3つです。
Environmentページ下部のCreateで環境を作成してTerminalからインストールします。
Terminalは環境名の右にある▶︎から開くことができます。
conda install pandas conda install matplotlib conda install sickit-learn
インストール完了後、AnacondaのHomeに移動します。
JupyterNotebookをInstall後Lunchボタンをクリックし、起動します。
右上の新規からPython3を選択して以下の画面が出力されたら準備完了です。
データ取得・ 表示
いよいよソースコードの詳細に入っていきます。
Jupyterでの動作はShift + Enterで確認できます。
まずは必要なライブラリをインストールします。
import requests import io import math import pandas as pd import matplotlib.pyplot as plt %matplotlib inline
取得する銘柄名とAlphaVantage登録時に取得したapi_keyを指定します。
今回はAppleを予測します。
symbol = 'aapl' api_key = 'XXXXXXXXXXXX'
APIを叩いて株価データを取得します。
データはcloseにのみ調整された項目が存在し分割などが考慮されています。
r = requests.get(f'https://www.alphavantage.co/query?function=TIME_SERIES_DAILY_ADJUSTED&symbol={symbol}&outputsize=full&apikey={api_key}&datatype=csv') r_df = pd.read_csv(io.BytesIO(r.content),sep=",") # 保存用に出力 r_df.to_csv(f'daily_data_{symbol}.csv') df = pd.read_csv(f'daily_data_{symbol}.csv') # 5行表示 df.head()
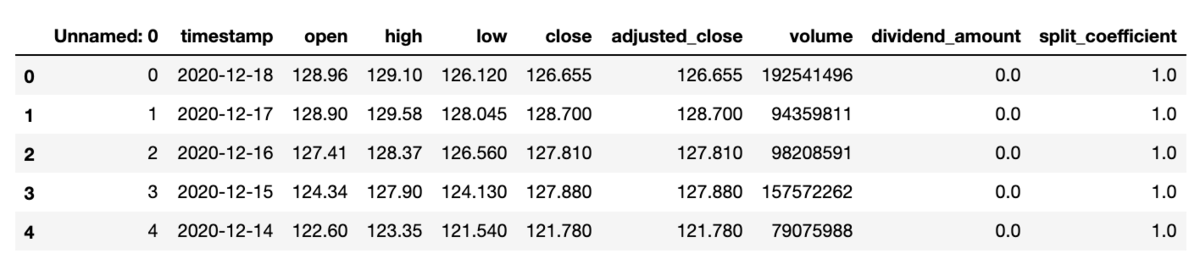
株価を表示させてみます。
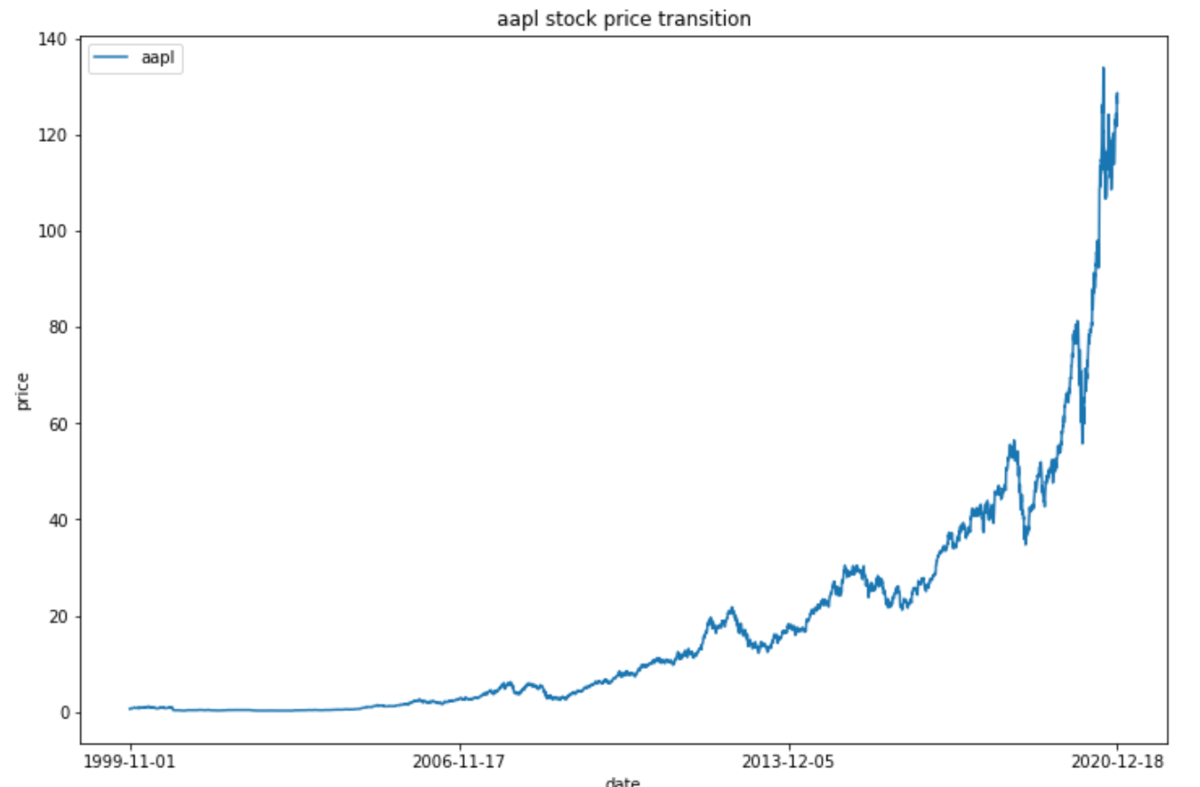
実行すると以下の画像のようなチャートが出力されます。
# 日時でソートする df = df.sort_values('timestamp') # plot用に約4分割した日付を取得 date_list = df['timestamp'].values xticklabels_list = [date_list[0], date_list[math.floor(len(date_list) / 3)], date_list[math.floor(len(date_list) / 1.5)], date_list[len(date_list) - 1]] # plot用にindexに日時を設定 plot_df = df.set_index(df['timestamp']) # plot処理 plt.figure(figsize = (12,8)) plt.plot(plot_df['adjusted_close']) plt.title(f"{symbol} stock price transition") plt.xlabel('date') plt.ylabel('price') plt.xticks(xticklabels_list) plt.legend([symbol]) plt.show()
前処理
前処理では主に以下を行います。
- close以外の調整値の算出
- 正解ラベルの作成
- 25日後の株価が上昇していれば正解ラベルを1にそうでない場合0にします。
- テクニカル指標を用いた特徴量の追加
- APIから取得できるテクニカル指標を使います。今回はとりあえず3つで..。
- 使用するテクニカル指標はSMA、RSIとBBANDSです。
では、まずはclose以外も分割で調整された値を設定します。
# close以外の調整値を算出 df['adjusted_rate'] = df['adjusted_close'] / df['close'] df['adjusted_open'] = df['open'] * df['adjusted_rate'] df['adjusted_high'] = df['high'] * df['adjusted_rate'] df['adjusted_low'] = df['low'] * df['adjusted_rate']
正解ラベルを作成します。
25日後と当日の終値の差を求め0より大きいかを判定しています。
df['25days_after_close'] = df['adjusted_close'].shift(-25) sub_close = df['25days_after_close'] - df['adjusted_close'] # 25日先の終値が当日の終値より大きければ0以上となる。 df['target'] = sub_close > 0 df['target'] = df['target'].astype(int)
SMA / RSI / BBANDSのAPIを叩いてテクニカル指標を取得します。
また取得したデータは株価データにマージしていきます。
どのようなデータ構造になっているかなどは割愛しますが、print(sma_5day)などを挟むとどのようなデータか分かるので確認してみてください。
##### # SMA(移動平均線) ##### # 5日平均 r = requests.get(f'https://www.alphavantage.co/query?function=SMA&symbol={symbol}&interval=daily&time_period=5&series_type=close&apikey={api_key}') sma_5day = r.json() sma5_df = pd.DataFrame() sma5_df['timestamp'] = sma_5day['Technical Analysis: SMA'].keys() # 辞書から値を取り出しリストにする sma5_list = [s['SMA'] for s in sma_5day['Technical Analysis: SMA'].values()] sma5_df['sma5'] = sma5_list # 25日平均 r = requests.get(f'https://www.alphavantage.co/query?function=SMA&symbol={symbol}&interval=daily&time_period=25&series_type=close&apikey={api_key}') sma_25day = r.json() sma25_df = pd.DataFrame() sma25_df['timestamp'] = sma_25day['Technical Analysis: SMA'].keys() sma25_list = [s['SMA'] for s in sma_25day['Technical Analysis: SMA'].values()] sma25_df['sma25'] = sma25_list # 75日平均 r = requests.get(f'https://www.alphavantage.co/query?function=SMA&symbol={symbol}&interval=daily&time_period=75&series_type=close&apikey={api_key}') sma_75day = r.json() sma75_df = pd.DataFrame() sma75_df['timestamp'] = sma_75day['Technical Analysis: SMA'].keys() sma75_list = [s['SMA'] for s in sma_75day['Technical Analysis: SMA'].values()] sma75_df['sma75'] = sma75_list # マージ処理 merge_df_5_25 = pd.merge(sma5_df, sma25_df) merge_df_5_25_75 = pd.merge(merge_df_5_25, sma75_df) merge_sma_df = pd.merge(df, merge_df_5_25_75) ##### # RSI(相対力指数) ##### r = requests.get(f'https://www.alphavantage.co/query?function=RSI&symbol={symbol}&interval=daily&time_period=14&series_type=close&apikey={api_key}') rsi = r.json() rsi_df = pd.DataFrame() rsi_df['timestamp'] = rsi['Technical Analysis: RSI'].keys() # 辞書から値を取り出しリストにする rsi_list = [r['RSI'] for r in rsi['Technical Analysis: RSI'].values()] rsi_df['rsi'] = rsi_list # マージ処理 merge_sma_rsi_df = pd.merge(merge_sma_df, rsi_df) ##### # BBANDS(ボリンジャーバンド) ##### r = requests.get(f'https://www.alphavantage.co/query?function=BBANDS&symbol={symbol}&interval=daily&time_period=25&series_type=close&nbdevup=2&nbdevdn=2&apikey={api_key}') bbands = r.json() bbands_df = pd.DataFrame() bbands_df['timestamp'] = bbands['Technical Analysis: BBANDS'].keys() # 辞書から値を取り出しリストにする r_u_b_list = [b['Real Upper Band'] for b in bbands['Technical Analysis: BBANDS'].values()] bbands_df['upper_band'] = r_u_b_list # マージ処理 merge_sma_rsi_bband_df = pd.merge(merge_sma_rsi_df, bbands_df)
APIの指標を追加しただけでは足りない気がしたので以下フラグを追加していきたいと思います。
- ゴールデンクロスフラグ(GC)
- パーフェクトオーダーフラグ(PO)
- ボラティリティー・ブレークアウトフラグ(BBO)
それぞれの定義は以下になります。
GC1:当日の5日線-25日線がプラスかつ 前日の5日線-25日線がマイナスの時フラグを1。
GC2:当日の25日線-75日線がプラスかつ 前日の25日線-75日線がマイナスの時フラグを1。
PO:当日の75日線-25日線がプラスかつ25日線-5日線がプラスの時フラグを1。
BBO:ボリンジャーバンドの±2σより終値の方が高い時フラグを1。
どれも定義としてあってるか不安ですが、とりあえず突き進みます。
# ゴールデンクロスフラグのリストを返す関数を定義 def calc_goldencross(series): goldencross_flag_list = [] for i, val in enumerate(series): if i == 0: # 最初は比較できないため0を設定 pre_val = val goldencross_flag_list.append(0) continue if (val > 0) and (pre_val < 0): # 当日がプラスかつ前日がマイナスの場合 goldencross_flag_list.append(1) else: goldencross_flag_list.append(0) pre_val = val return goldencross_flag_list # 5日線-25日線 sub_sma5_sma25 = merge_sma_rsi_bband_df['sma5'].astype(float) - merge_sma_rsi_bband_df['sma25'].astype(float) merge_sma_rsi_bband_df['sub_sma5_sma25'] = sub_sma5_sma25 # 25日線-75日線 sub_sma25_sma75 = merge_sma_rsi_bband_df['sma25'].astype(float) - merge_sma_rsi_bband_df['sma75'].astype(float) merge_sma_rsi_bband_df['sub_sma25_sma75'] = sub_sma25_sma75 # ゴールデンクロスフラグ算出 merge_sma_rsi_bband_df['goldencross_flag1'] = calc_goldencross(sub_sma5_sma25) merge_sma_rsi_bband_df['goldencross_flag2'] = calc_goldencross(sub_sma25_sma75) # パーフェクトオーダーフラグ算出 sub_po_flag = (merge_sma_rsi_bband_df['sub_sma5_sma25'] > 0) & (merge_sma_rsi_bband_df['sub_sma25_sma75'] > 0) merge_sma_rsi_bband_df['purfectorder_flag'] = sub_po_flag.astype(int) # ボラティリティー・ブレークアウトフラグ算出 sub_uband_close = merge_sma_rsi_bband_df['upper_band'].astype(float) - merge_sma_rsi_bband_df['adjusted_close'].astype(float) merge_sma_rsi_bband_df['breakout_flag'] = sub_uband_close < 0 merge_sma_rsi_bband_df['breakout_flag'] = merge_sma_rsi_bband_df['breakout_flag'].astype(int)
データ絞り込み
残りもわずかとなってきました。
予測で必要となるデータに絞り込んでいきます。
正解フラグは25日先の株価が上昇しているかを判定しているため直近25日のデータを学習データから除きます。
そして直近の25日は予測データとして用いたいと思います。
# 25日先の情報がないレコードを削除する drop_25days_after_close = merge_sma_rsi_bband_df.dropna(subset=['25days_after_close']) # 予測対象レコードも抽出 extract_predict_25days = merge_sma_rsi_bband_df[merge_sma_rsi_bband_df['25days_after_close'].isnull()] # カラムの絞り込み columns = ['adjusted_open', 'adjusted_high', 'adjusted_low', 'adjusted_close', 'volume', 'dividend_amount', 'split_coefficient', 'sma5', 'sma25', 'sma75', 'sub_sma5_sma25', 'sub_sma25_sma75', 'goldencross_flag1', 'goldencross_flag2', 'purfectorder_flag', 'rsi', 'upper_band', 'breakout_flag'] train_df = drop_25days_after_close[columns] target_df = drop_25days_after_close['target']
学習・予測
ランダムフォレストを用いて学習 / 予測を行っていきたいと思います。
ランダムフォレストは特徴量の寄与度を求めることができるため、よくお世話になります。
ライブラリをインストールします。
from sklearn.model_selection import train_test_split from sklearn.ensemble import RandomForestClassifier from sklearn.metrics import accuracy_score, confusion_matrix
訓練データとテストデータに分割し、ランダムフォレストの学習器に渡します。 test_size=0.1 とするとAppleの場合約500日分がテストデータとなります。
#トレーニングデータとテストデータを分割 # 約2月分をテストデータにする train_data, test_data, train_target, test_target = train_test_split(train_df, target_df, test_size=0.1) #ランダムフォレストに学習データを格納 clf = RandomForestClassifier() clf.fit(train_data, train_target)
テストデータで予測を実施して結果を確認しましょう!
実行すると誤差はあると思いますが90%前後になると思います。
predict = clf.predict(test_data) #結果を表示 ac_score = accuracy_score(test_target, predict) print("正解率", ac_score)
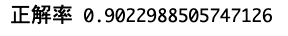
混合行列も確認してみます。
cm = confusion_matrix(test_target, predict) cm_df = pd.DataFrame(index=['Positive', 'Negative']) cm_df['Positive'] = cm[0] cm_df['Negative'] = cm[1] cm_df

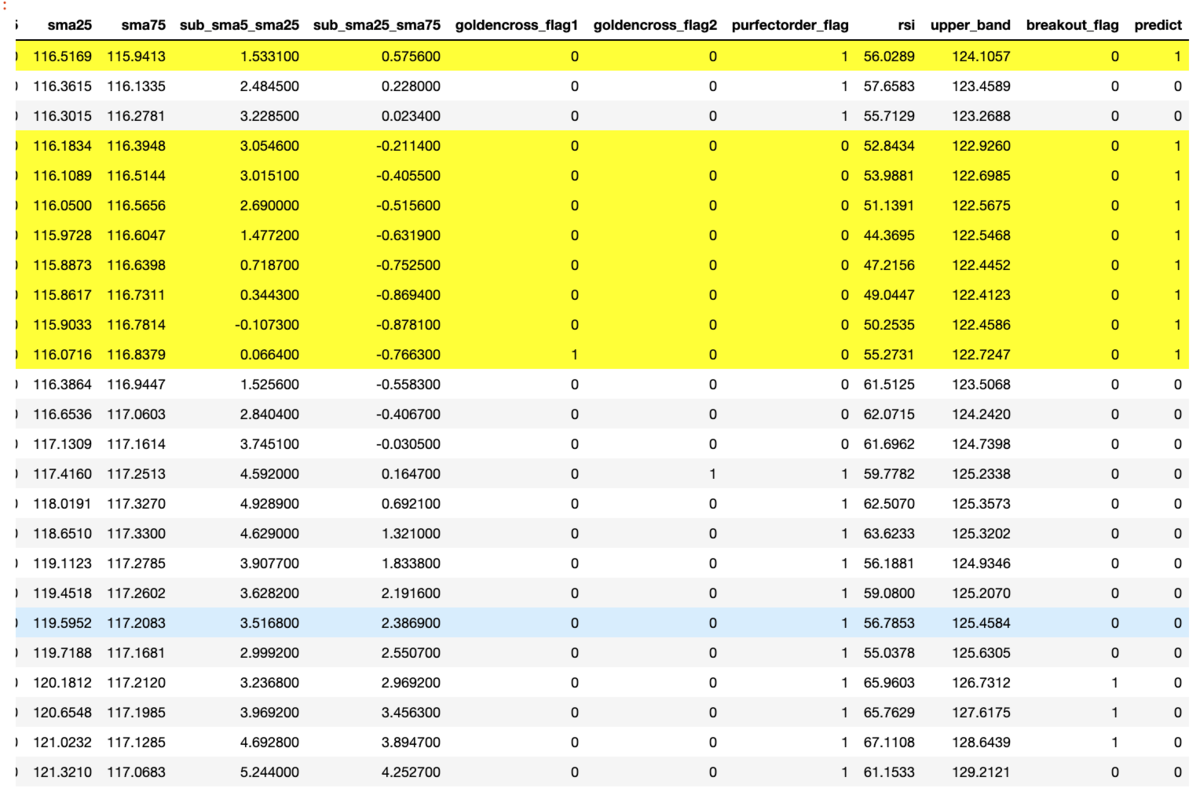
先ほどデータ絞り込みのところで作成した、直近25日の情報を予測させてみましょう。
実行すると以下のpredictが1の場合黄色のデータが表示されます。
直近の日付が一番下のレコードのため、現時点は買わない方が良いという判定になりました。
predict_df = extract_predict_25days[columns] predict = clf.predict(predict_df) predict_df['predict'] = predict def highlight(x): # predictが1のレコード色を黄色にする highlight_flag = 0 if x['predict'] == 1: highlight_flag = 1 return ['background-color: yellow' if highlight_flag == 1 else '' for _ in x] predict_df.style.apply(highlight, axis=1)
まとめ
思ったよりもいい精度が出たため、バグってそうで怖いです!
本当に予測できているのかは今後温かい目で見守っていきたいと思います。
ちなみに上記処理をgproでも試してみたところ、正解率が約95%かつpredictが1になっていたのでとりあえず買ってみることにしました。
さらに今後以下の3つを行えばより良い精度を目指せる...と思います。
- 学習時のパラメーターチューニング
- 特徴量の追加と特徴量の寄与度算出による試行錯誤
- ランダムフォレスト以外のxgboostやディープラーニングを用いた精度調査(特徴量の正規化等も必要となってくる)
今回は米株でしたが国内の予測を行いたい場合は伊奈さんの記事を参考にデータを取得すればスムーズに進みそうなのでご紹介します。 tec.tecotec.co.jp