本投稿は TECOTEC Advent Calendar 2020 の20日目の記事です。
投資戦略システム事業部の亀井です。
2020/07頃にサーバサイドエンジニアとして中途で入社し、現在は大尊敬する伊奈先生1の下でお仕事させていただいております。
私の職場には、エンジニアの技術を生かして華麗に、スタイリッシュに、そしてクールにお金を稼ぎだす人材がたくさんいます。
まさに世の中のかっこいいオトナを体現する方々なのですが、このエントリーを読むあなたもそんなオトナになりたくありませんか?
社会に出る前は夢に描いていた理想のオトナ像。
社会人として戦う日々の中で、その理想は淡く、儚いものだとあきらめてしまったのはいつの頃だったでしょうか。。
そんなポエムをかましてみたところで、要はかっこいいオトナになりたいんです!
心の底からピュアな憧れをいただいた心清らかな少年がその一歩を踏み出すべく、
楽して稼ぐ
という欲望丸出しのコンセプトで、エンジニアの技術を生かして華麗に、スタイリッシュに、そしてクールにお金を稼ぎたい方に向けた私の試みをご紹介したいと思います。
動機は不純ですが、内容はいたって清純です。よかったら見ていってください。
※1. 稼げるとは言ってません
※2. 楽して稼ごうというのは邪心ではありません。ロマンです。
目次
どうやって稼ぐのか?
下記仕組みで市場からお金をいただくことを目論見ます。2
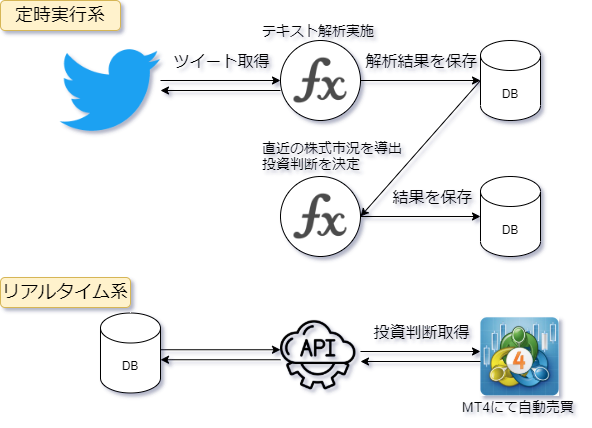
概要
近年のSNSの発達とともに、SNSと金融市場の相関を示すような論文が数多く発表されています。
今回は、その中でも多くの論文から引用された実績のあるものに着目しました。
概要としては、Twitterのツイートを利用してダウ平均株価の予測精度がおよそ80%を超えるような結果が得られたという旨のものです。
予測精度80%超えという驚異の数字を叩き出したこの論文のエッセンスを拝借し、
- Twitterから情報取得
- 取得した情報から相場の市況を解析
- その結果を用いてMetaTrader4と呼ばれる金融商品取引プラットフォームにて自動売買システムを稼働
という試みです。今回のエントリーでは1. Twitterから情報取得をターゲットについてご紹介しようと思います。(2にもちょっぴり足を突っ込みます)
元ネタ
2010年の下記論文が思い付きの元となっています。 www.sciencedirect.com
英文読むなんてつらいよー、Google翻訳さん使えってことですか?
という方向けにざっくり説明しておきます。詳しくはやっぱり元文を読むにかぎります。
- 何やったか:Twitterから感情に関わる情報を抽出し、株価変動を予測する試み
- 結論:時系列データの予測モデルに、Calm(平穏)の感情データを加えると、予測精度が86.7%まで高まった
【解析手順】
- Twitterのツイート文を収集
- ツイート文をネガティブ・ポジティブの分類
- 同時にツイートを6種の感情(平穏、警戒、確信、活気、善意、幸福)に分類
- 感情の解析結果を時系列データに数値化し、ダウ平均株価との相関性を調査
- 時系列データの予測モデルに感情の解析データを加え、予測精度を計測
Twitterからの情報取得
ここでは、Twitter APIから情報を取得して、データを可視化するところまでやってみます。
必要なもの
今回はTwitter APIを利用します。必要なものは下記です。
- API key
- API secret key
- Access token
- Access token secret
- Twitter愛
- 夢(実現したいこと)
ほんとに必要な1~4を手に入れるためにdeveloper申請をする必要があります。
審査では、
「なんでAPI使いたいのー?」
「データを何につかうのー?」
みたいなことを聞かれるので、愛と夢を以って答えてあげてください。
下記を参考にさせていただきました。
ちなみに、ここでは英語で申請しているようでしたが、私は全部日本語で回答してスルッと通りました。
www.itti.jp
ツイート取得の前に
必要なものの準備ができたら、さっそく実際にツイートを取得!
といきたいところですが、あんまり気乗りしないトリセツを前もって読んでおくことにしましょう。
まず、無料で使えるのはStandard APIと呼ばれているもののようです。
developer.twitter.com
その中でも今回ツイート取得に利用させていただくのは、Standard search APIと呼ばれているものです。
developer.twitter.com
気になる利用制限は下記です。
- 1回のリクエストで取得できるツイート数は100件まで
- 15分あたりのリクエスト可能回数は450回
- 検索で取得できる期間は直近7日間分
まとめると、1秒当たり50ツイート取得可能です。
1日で432万ツイート、1ヶ月で1.29億ツイート、1年で15.8億ツイート取得できる計算になります。
たくさん取れるように見えますが、何といっても7日間しか遡れないのがネックです。
私はAWSを使って、定時実行系として時間をかけてデータを貯めていってあげる仕組みを整えてあげることにしました。
言うまでもなく、お金を出せば制限はどんどん解除されていきますが、一個人が無邪気に使いまわすにはハードルが高そうです。
Enterprize向けはもはや価格すら書かれておりません。
要件に合わせて使うプランを変えてねー、とTwitter社様はおっしゃっております。
価値あるデータハウスになれるとほんとにステキな商売になりますね。
developer.twitter.com
ツイートを取得してみる
さて、このStandard search APIですが、様々な条件でツイートを取得することができます。
| params | 指定必須か否か | 概説 |
|---|---|---|
| q | required | 検索クエリです。Twitterでツイート検索する時と同じイメージです。 |
| geocode | optional | つぶやかれたツイート位置を、緯度・経度・半径で絞ることができます。 |
| lang | optional | ツイートされた言語を指定できます。 |
| locale | optional | クエリの言語を指定できますが、現在はjaしか指定できないようです。(なんでだろ?) |
| result_type | optional | 取得するツイートの種類が選択できます。 recent:最新のツイート popular:人気のツイート mixed:recent と popular |
| count | optional | ツイートの取得件数を指定できます。デフォルトは15件、最大100件を指定することができます。 |
| until | optional | 取得対象のツイートの期間を指定できます。最大7日間しか遡れません。 |
| since_id | optional | 指定したツイートのIDより大きなIDを持つツイートを取得します。 最大100件ずつしか取れないので、ツイードIDはどこまで取ったっけ?という道しるべになります。 |
| max_id | optional | 指定したツイートのIDより小さなIDを持つツイートを取得します。since_idと使い方は同じイメージです。 |
| include_entities | optional | entityを含んで取得するか否かを選択できます。 |
ここからはデータ分析がお得意なPythonさんを使っていきます。
必要なパッケージはAPIアクセス用にrequests-oauthlib、データ整形用にpandasを使っていきます。
pip install pandas requests-oauthlib
APIへのアクセスは今後他のAPIも利用することを見越して、class化しておきます。
import json
import time
import logging
from datetime import date, timedelta
import pandas as pd
from requests_oauthlib import OAuth1Session
class TwitterApiAccessor:
"""
Twitter API へのアクセスを実施するクラス
"""
STANDARD_SEARCH_API_URL = "https://api.twitter.com/1.1/search/tweets.json"
def __init__(self,
api_key: str,
api_secret_key: str,
access_token: str,
access_token_secret: str):
self.api = OAuth1Session(api_key, api_secret_key, access_token, access_token_secret)
@property
def get_standard_search_api_url(self) -> str:
return self.STANDARD_SEARCH_API_URL
@staticmethod
def parse_params(params_str):
param_dict = {}
for query in params_str.lstrip('?').split('&'):
param_name, val = query.split('=', 1)
param_dict[param_name] = val
return param_dict
def get_tweet(self,
key_word: str,
latitude: float = None,
longitude: float = None,
radius: float = None,
lang: str = 'ja',
result_type: str='recent',
count: int = 15,
until: date = None,
num_requests: int = 1) -> pd.DataFrame:
"""
Standard search APIを利用したツイートの取得
ツイート数はcount * num_requestsで導出される
Args:
key_word: 検索クエリ
latitude: 緯度
longitude: 経度
radius: 半径(km)
lang: ツイートの言語
result_type: 取得対象ツイート
count: 取得対象ツイート件数
until: 取得対象期間
num_requests: リクエスト回数
Return:
pd.DataFrame(tweet_list): pandas形式にしたツイート取得結果
"""
# パラメータの作成
params = {
'q': key_word,
'lang': lang,
'result_type': result_type,
'count': count
}
if latitude and longitude and radius:
params['geocode'] = f'{latitude},{longitude},{radius}km'
if until:
if abs(date.today() - until) > 7:
until = date.today() - timedelta(days=7)
params['until'] = until.strftime('%Y-%m-%d')
# ツイートの取得と格納
# 15分間で450回のリクエスト制限があるため、適宜sleepを入れる
tweet_list: list = []
start: float = time.time()
idx: int = 0
for _ in range(num_requests):
res = self.api.get(self.get_standard_search_api_url, params=params)
response = json.loads(res.text)
if res.status_code == 200:
tweet_list.extend([t for t in response['statuses']])
else:
raise f'Invalid status code: {response.status_code}'
# next_resultsに格納された値をparameterとして作り直す
# そうすることで、ツイートを重複取得してしまわないで済む
if 'next_results' in response['search_metadata'].keys():
next_results = response['search_metadata']['next_results']
params = self.parse_params(next_results)
else:
break
idx += 1
elapsed_time = (time.time() - start) / 60 # 単位はmin
if elapsed_time < 15 and 450 <= idx :
logging.warning('Reached access limit. Sleep 15[min]')
time.sleep(900)
start = time.time()
idx = 0
return pd.DataFrame(tweet_list)
今回は最近のホットワードであるgotoというキーワードでツイートを少しだけ取得してみようと思います。
Executorという実行用のクラスを適当に作って、ここからTwitterApiAccessorのメソッドを呼んであげます。
class Executor:
def __init__(self,
api_key: str,
api_secret_key: str,
access_token: str,
access_token_secret: str):
self.twitter_accessor = TwitterApiAccessor(api_key, api_secret_key, access_token, access_token_secret)
def get_tweet(self, word: str):
return self.twitter_accessor.get_tweet(word, num_requests=1, count=1)
APIをシンプルに叩いて取得できたレスポンスは下記です。statusesの中に実際のツイート内容があるのでこちらを見ていくことになります。
{
"statuses": [
""" ツイート内容を晒すのは憚られるので割愛 """
],
"search_metadata": {
"completed_in": 0.027,
"max_id": 1339820092821970944,
"max_id_str": "1339820092821970944",
"next_results": "?max_id=1339820092821970943&q=goto&lang=ja&count=1&include_entities=1&result_type=recent",
"query": "goto",
"refresh_url": "?since_id=1339820092821970944&q=goto&lang=ja&result_type=recent&include_entities=1",
"count": 1,
"since_id": 0,
"since_id_str": "0"
}
}
get_tweetを呼んで、pandasのDataFrame形式で受け取ったデータフレームの情報は下記です。
実際のツイートはこの中のtextというカラムに格納されています。
<class 'pandas.core.frame.DataFrame'> RangeIndex: 1 entries, 0 to 0 Data columns (total 25 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 created_at 1 non-null object 1 id 1 non-null int64 2 id_str 1 non-null object 3 text 1 non-null object 4 truncated 1 non-null bool 5 entities 1 non-null object 6 metadata 1 non-null object 7 source 1 non-null object 8 in_reply_to_status_id 0 non-null object 9 in_reply_to_status_id_str 0 non-null object 10 in_reply_to_user_id 0 non-null object 11 in_reply_to_user_id_str 0 non-null object 12 in_reply_to_screen_name 0 non-null object 13 user 1 non-null object 14 geo 0 non-null object 15 coordinates 0 non-null object 16 place 0 non-null object 17 contributors 0 non-null object 18 retweeted_status 1 non-null object 19 is_quote_status 1 non-null bool 20 retweet_count 1 non-null int64 21 favorite_count 1 non-null int64 22 favorited 1 non-null bool 23 retweeted 1 non-null bool 24 lang 1 non-null object
ツイートを分析してみる
さて、ツイートを取得する試みが無事成功したところで、今回はStep2にもちょっぴり足を踏み入れておこうと思います。
先日(2020/12月中旬頃)発表されたGoToトラベルの全国停止の一報を受けた、世間の反応をTwitterのツイートから可視化してみます。
ここで遊んでみるのは、形態素解析と呼ばれる自然言語処理の一種です。
ざっくり説明すると、文章を形態素と呼ばれる、言葉の意味がわかるレベルでの最小単位まで分解して解析するというものです。
では、どんな声がTwitterに多いのか、可視化してみましょう。

4500件しかツイートを使っていないので偏りが感じられるのと、日本語の前処理(クレンジング)が甘いので違和感のあるワードもありますが、
ううぅぅ。。
なんとも目を覆いたくなるようなネガティブワードがたくさん。。。
時期的にもGoToに対してネガティブな感情を持っているのは覚悟の上でしたが、、SNSってこわいですねぇ。。
と、こんな感じで次回は取得したデータを色々とこねくり回してみることにチャレンジしようと思います。
おわりに
今回は準備段階のStep1について紹介する内容となりました。
次回はStep2として取得したツイートをテキスト解析して質の高いデータに仕立て上げる所をご紹介したいと思います。
最後までご覧いただきありがとうございました。
テコテックは一緒に働ける人材を募集しています。かっこよく、スタイリッシュに、クールに稼ぎたいという煩悩をお持ちの方がいらっしゃいましたら、一度自分と向き合う旅に出てみるか、下記のリンクからご応募ください。 www.tecotec.co.jp
-
冒頭でご紹介した尊敬する伊奈先生の開発者ブログの記事を紹介しておきます。数ある開発者ブログの記事の中でも、先生の記事は非常に興味深いものとなっておりますので、ぜひご一読ください。tec.tecotec.co.jptec.tecotec.co.jp
↩ -
Twitterの商標およびそのロゴ、Twitterの「T」ロゴ、Tweet、Twitterの青い鳥は、Twitter, Inc.の米国およびその他の国における登録商標または商標です。↩