本投稿はTECOTEC Advent Calendar 2022の5日目の記事です。
こんにちは。2年ぶり3回目の寄稿となります、決済認証システム開発事業部の杉本です。
今回は、長時間かかる処理を実施する際にあると嬉しい「あるもの」を作ってみた、という記事です。
改訂2万記録
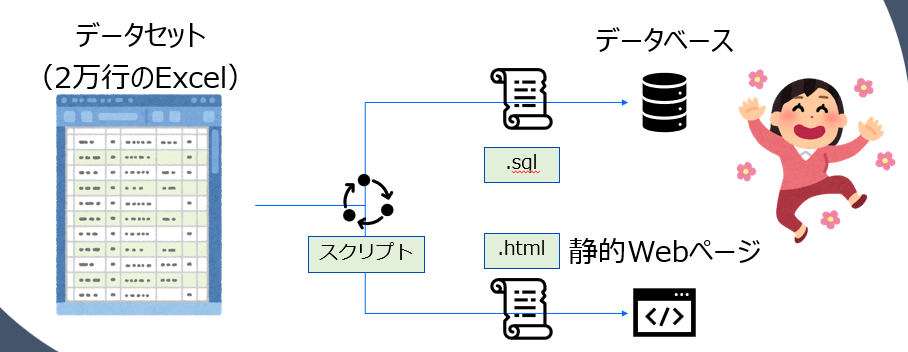
さて、私はプライベートのボランティア活動でもシステム開発に携わっているのですが、その中で、約2万件のリストを取り扱うことがあります。年に数回。
Excelで共有されるそのリストを、一方ではサービスが参照するデータベースに登録し、他方で、HTMLファイルにtable形式で記述する必要がありました。
量が多いものですから、とても手作業で用意することは考えられませんが、かと言って年に数回の、それも手元で完結するような作業に、きちんとしたデータインポートシステムを構築するのも勿体ない、という具合です。
そこで、 リストを読み込んで、SQL(INSERT文)とHTMLを出力するようなスクリプト を作ることにしました。
出来上がったスクリプトがこちらです。*1
もちろん、変数名やテーブル名は実際のものとは異なります。また、一部を省略しています。
#!/bin/bash # データセットのTSVファイルを読み込んで、静的HTMLのリストと、INSERT文のSQLを生成するスクリプト # データは.xlsxで渡されるが、Excelで開いて「テキスト(タブ区切り)」で保存し、文字コードをUTF-8に直したものを利用する # CSVファイルでは、名称にカンマを含むレコードで項目が異常になるため、TSVを対象とする # for use ... $ bash ./import_list.sh 100 2 ./100.txt SCRIPT_DIR=$(cd $(dirname $0); pwd) EVENT_NUMBER=$1 EVENT_DURATION=$2 TSV_PATH=$3 # INSERT文を記載するsqlファイルを作成 targetSql="./insert_data_${EVENT_NUMBER}.up.sql" sqlInsert="INSERT INTO participants(...) VALUES" echo ${sqlInsert} > ${targetSql} # イベントの日数分のhtmlファイルを作成 for i in `seq 1 ${EVENT_DURATION}` do cat << EOF > ./${EVENT_NUMBER}_${i}.html <html> <head> <meta http-equiv="Content-Type" content="text/html; charset=UTF-8"> ... </head> <body> <table> <thead> ... </thead> <tbody> EOF done lines=$(wc -l < ${TSV_PATH}) bulkCount=0 # 指定されたTSVファイルを読み込んで、1行ずつ回し、.htmlファイルと.sqlファイルに情報を載せていく while IFS=$(echo -e '\t') read -r id receiptNo name nameKana code day area block space backnumber placeName place; do ... targetFile="./${EVENT_NUMBER}_${dayCount}.html" # 名称にカンマを含む場合は、両端にダブルクォートがついているため取る # ダブルクォートでマッチさせると、意図的にダブルクォートを含む名称で過剰なtrimが発生するためこの対応としている if [ "$(echo ${name} | grep ',')" ]; then name=${name:1:-1} fi # htmlファイルへの書き込み echo "<tr>" >> ${targetFile} echo " <td>${dayCount}</td>" >> ${targetFile} echo " <td>${area}</td>" >> ${targetFile} ... echo "</tr>" >> ${targetFile} # sqlファイルへの書き込み。1,000行ずつのbulkInsert # ダブルクォートを含む名称への対応はできていないので、生成後手動で調整のこと if [ $((bulkCount % 1000)) -eq 0 ]; then echo "(${EVENT_NUMBER}, ${dayCount}, '${area}', '${block}', \"${name}\", ${receiptNo});" >> ${targetSql} echo "" >> ${targetSql} echo ${sqlInsert} >> ${targetSql} elif [ $((bulkCount + 1)) -eq ${lines} ]; then echo "(...);" >> ${targetSql} else echo "(...)," >> ${targetSql} fi done < ${TSV_PATH} # 日数分のhtmlファイルの末尾を追加 for i in `seq 1 ${EVENT_DURATION}` do targetFile="./${EVENT_NUMBER}_${i}.html" echo " </tbody>" >> ${targetFile} echo " </table>" >> ${targetFile} echo "</body></html>" >> ${targetFile} done
進捗どうですか?
さてこのスクリプトですが、2万件のデータを処理した場合、PCの演算能力に余裕があっても、10分以上かかるものになっていました。
実行するとどうなるかと言うと……
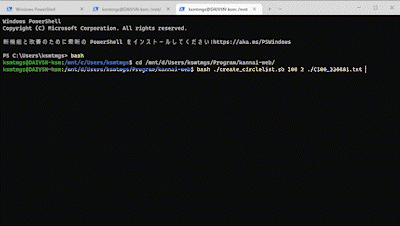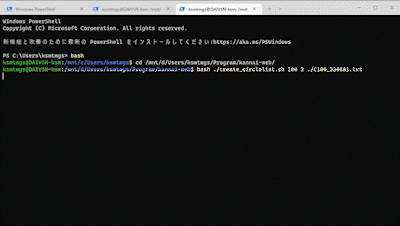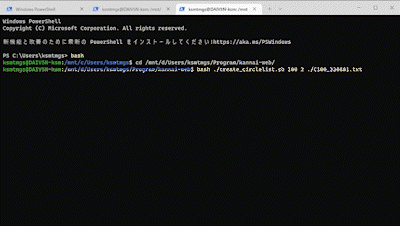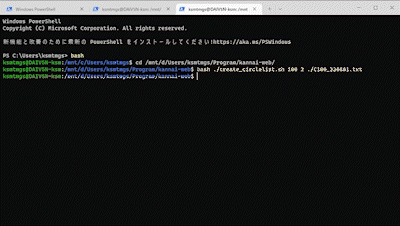
状況がまったくわからないんですね。
上に載せたアニメーションGIF*2は、撮影用に1,000件のデータ処理(1分弱)を行った際の録画を、5倍速にしたものですが、これでも「何も反応がない」ことの不安は感じられるかと思います。
では、処理したデータのIDをログに吐き出すようにしてみると、どうでしょうか。
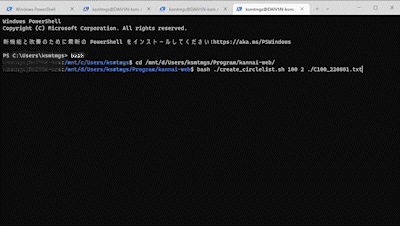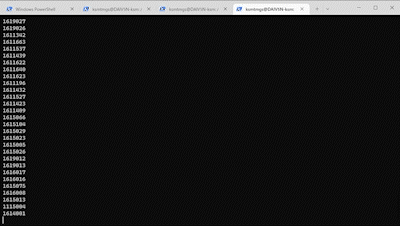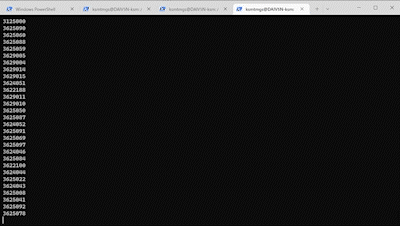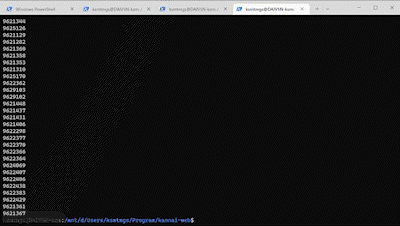
同じく、1,000件・5倍速のGIFアニメーションとなります。
処理が進んでいること=スクリプトが死んでいないことはわかるようになりました。ですが、今どこまで処理できて、あとどれくらいかかるのかがわかりません。実際には10分以上もかかる処理で、これを眺めながら待ち続けるのは、やはり難しいと言わざるを得ないでしょう。
ここで、ターミナルを使って長い処理が行われるとき、利用者に不安を感じさせない仕組みがあることを思い出しました。

npmやcomposerなど、パッケージをインストールしたり、gitやamplifyのように、リモートリポジトリからローカルに拾ってきたり。
長くかかることが予想される処理には、きちんと進捗を示す出力があって、特にゲージが伸びていくものは、視覚的・直感的に状況を把握することができます。
例に挙げたこれらが、今回のスクリプトよりはるかに優れて複雑であることは間違いない。それでも「ターミナルで実行するもので、進捗を示すことができる」のであれば、今回のスクリプトにも組み込むことができるのではないでしょうか。
ということで、本稿でご紹介するのは、「プログレスバー」の作り方になります。
CR行頭復帰
プログレスバーで進捗を表現するにあたって、最低限必要なものは「全体量」と「現在の処理済み量」の2点と考えられます。分数の分母と分子ですね。
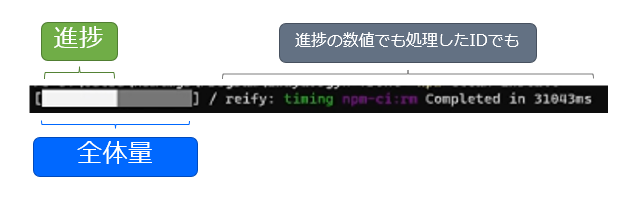
今回のスクリプトでは、最初に lines として全行数を取得しており、また1行ずつ処理する度に bulkCount を増やしているので、どちらも参照は容易です。
その値を、たとえばバーを20文字ぶんの長さにするなら、x/20 に約分/倍分して、その文字数ぶん ■ なり = なりで続けることで、バーを表現することはできます。
しかし、これを出力していくと、先ほどの「IDが吐かれ続ける」ものが「プログレスバーが吐かれ続ける」に変わるのみです。
バーが伸びていくように表現するために、どのような工夫が必要なのでしょうか。
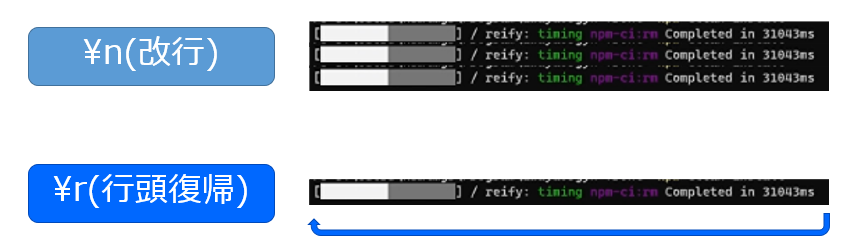
その鍵となるのが、本稿の表題に据えた Carriage Return です。
ログを出力するときには、改行 \n を加えることで、ポインタを次の行に送っていました。その代わりに行頭復帰 \r をすることで、ポインタをその行の先頭に戻し、行の記述を上書きする形で出力することができるのですね。
ということで、先ほどのスクリプトに、プログレスバーの表現を加えてみると、以下のようになります。
# プログレスバーを表示 PROGRESS_LENGTH=20 progressF=$(echo ${bulkCount} ${lines} | awk ‘{printf(“%.2f”, $1/$2*100)}’) # 進捗度合のfloat値を算出 progressI=$(echo ${progressF} | awk ‘{printf(“%d”, $1)}’) # 進捗度合をintegerに変換 barLength=$((${progressI}/(100/${PROGRESS_LENGTH}) )) # 進捗バーの長さを算出 bar="$(yes = | head -n ${barLength} | tr -d '\n')" # 進捗バーの長さ分、「=」を繰り返す if [ ${barLength} -lt ${PROGRESS_LENGTH} ]; then blank="$(yes . | head -n $((${PROGRESS_LENGTH} - ${barLength} - 1)) | tr -d '\n')" # 進捗が総量に満たないなら、残りを「.」で埋めて bar="${bar}>${blank}" # 矢印になるように先頭に「>」をつける fi printf "\r[%s] %s (%s/%s)" ${bar} "${progressF}%" "${bulkCount}" "${lines}" # 行頭復帰して、バーと進捗/総量を出力する
改めて、スクリプトを実行してみると……
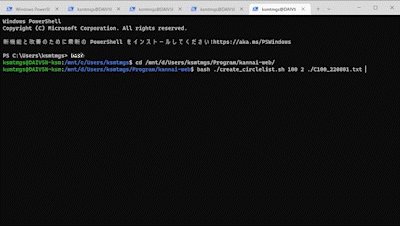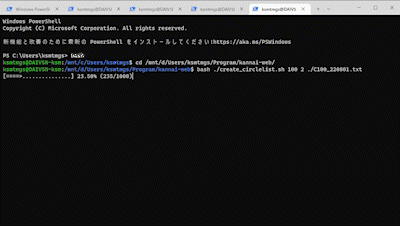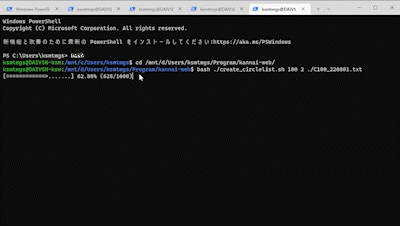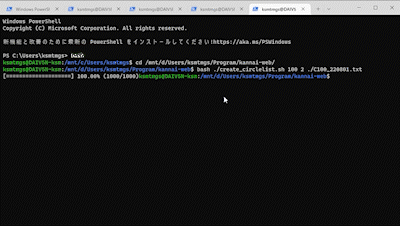
はれて、処理の進捗がわかるようになりました。
おわりに
エンジニアであれば、CR・LFというものは馴染みがある*3と思いますし、環境構築などでターミナル上のプログレスバーを目にすることもあるはずです。
ですが、お恥ずかしながら、プログレスバーの挙動がCRによって実現される、ということには思い至りませんでした。おそらく、制御コードの挙動を本質的に理解していれば、すぐに気づくことができたのだろうと感じます。
ふだん何気なく見たり使ったりしているものにも、「在るものは作れる」という意識で目を向けてみると、新たな発見や学びがあるものですね。
Do It Yourself!!