本投稿は TECOTEC Advent Calendar 2024 の13日目の記事です。
証券フロンティア事業部の吉澤です。今年新卒として入社しました。普段はバックエンドエンジニアとしてPythonでシステムの保守運用・開発を行っています。
最近、業務外での個人的な活動として生成AIのAPIを用いたPDF要約アプリケーションを作成しました。なお、業務外でのアプリケーション制作は初めての体験になりますので、今回はその体験記として開発の背景や過程を紹介したいと思います。
開発の背景
私は今年度、証券フロンティア事業部に配属され、現在カビュウの保守運用・開発に携わっています。カビュウは株式投資管理・分析アプリで、個人投資家の方々が手軽に自分の証券口座を管理・分析することができるツールです。配属当初、私は株式投資に関する知識がほとんどなかったのですが、業務を通じて徐々に株式投資への理解が深まり、個人投資家の方々の気持ちが理解できる様になっていきました。
決算報告書をタイパよく把握したい
そんな中で、「決算報告書を要約する様なツールを作れると面白いんじゃないか」と思うようになりました。通常、企業の決算報告書の資料はPDFで何ページにも渡っており、私のような素人はもちろん、個人投資家であっても、1つの資料を読むのには時間がかかるかと思います。そこで、生成AIを用いて「長い決算報告書の内容からぱっと見で良い決算か悪い決算か知れたら便利そうだな」と考えるようになりました。また、日常生活でよくChatGPTを使っているのですが、「そろそろ生成AIをAPI経由で使いたい」という思いと、生成AIをより効果的なツールとして活用するのに必要な、プロンプトエンジニアリングにも入門したいと思いました。
これらの背景から、生成AIのAPIを用いてPDFの要約を行うアプリケーションを開発することにしました。
想定用途
とりあえず作ってみようという動機なのですが、一応用途や要件をはっきりさせておきます。 要件は、やんわりと「発表された決算報告の概要をぱっと見で把握できる」とし、 用途としては、「誰よりも早く良い決算を見つける」、「話題の銘柄の直近の決算を手短に確認する」というものを想定します。
決算シーズンになると、決算は1日に何百もの、様々な企業から発表されることになります。そんな中で、決算の良い企業を簡単に見つけられるとしたら、ある程度の需要があるのではないかと想像してます。
使ったもの
- 生成AI: SambaNova Cloud API + Llama 3.1 405B
- 言語: Python
- 外部ライブラリ: openai, pdfplumber
- エディタ: Visual Studio Code
生成AIのAPIに何を使うかを考えたのですが、「なるべくお金がかからない・性能の高いもの」という条件で探したところ、SambaNova Cloud APIというものを利用して、Llama 3.1 405Bを使うのが良いと思いました。Llama 3.1 405Bは、Meta社の開発したオープンソースLLMで、ChatGPTやClaudeなどのLLMと遜色ない性能であると報告されています。また、SambaNova Cloudは、2024年9月10日時点で最速のAI推論プラットフォームと評価されているらしいです。つまり、AIからの返事が速く返ってきやすいということなのですが、今回の想定用途では1日に500もの決算報告書を読む可能性もあるので、早く処理が終わるのであればうれしいですね。 プログラミング言語は業務でも扱っているPythonを使います。使用するOpenAIのライブラリはOpenAI社が提供している公式ライブラリで、OpenAIのLLMに限定されず他のLLMも汎用的に扱えるようで、SambaNova CloudAPIでも使用できるようです。pdfplumberは、APIにPDFの内容を送信する際の前処理を行うために使います。
前準備
SambaNova Cloud APIを使うには、APIキーを取得する必要があります。
APIトークンは、SambaNova Cloud にログインし、使いたいLLMを選択後、Generate New API Keyを押すだけで取得できます。
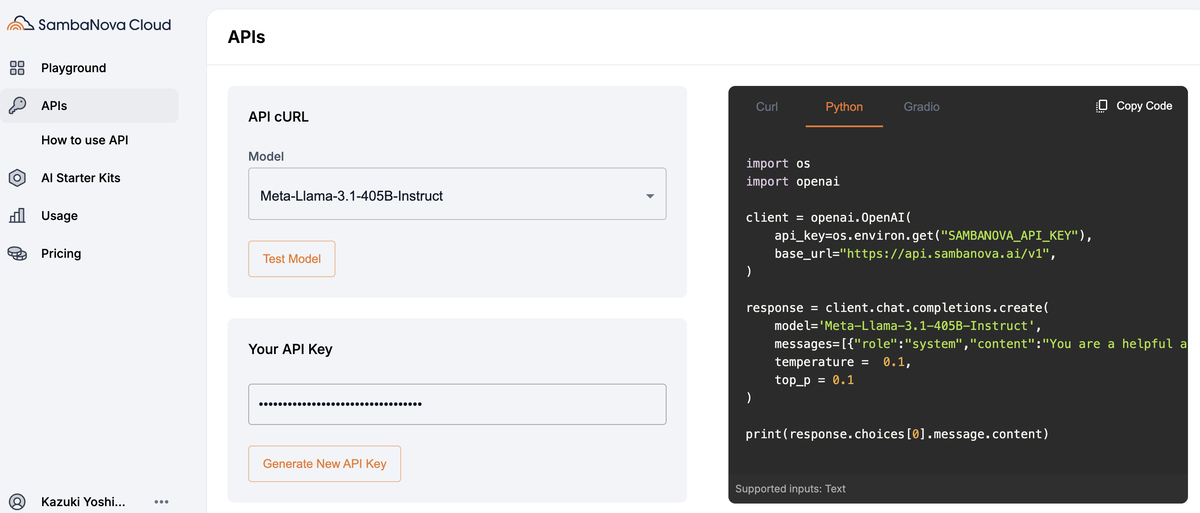
ちなみにPythonで実装する場合は、APIキー環境変数に設定し右のサンプルコードをそのままコピペすれば、APIを通してAIにアクセスできます。
app.py
import os import openai client = openai.OpenAI( api_key=os.environ.get("SAMBANOVA_API_KEY"), base_url="https://api.sambanova.ai/v1", ) response = client.chat.completions.create( model='Meta-Llama-3.1-405B-Instruct', messages=[{"role":"system","content":"You are a helpful assistant"},{"role":"user","content":"Hello"}], temperature = 0.1, top_p = 0.1 ) print(response.choices[0].message.content)
$ python app.py Hello! It's nice to meet you. Is there something I can help you with, or would you like to chat?
プロンプト
実際にAPIにリクエストを送るAIへの指示文の部分は下記の部分なのですが、temperature、top_pってなんだろう・・・となったので調べてみたところ、下記のサイトに簡単に書かれていました。
messages=[{"role":"system","content":"You are a helpful assistant"},{"role":"user","content":"Hello"}],
temperature = 0.1,
top_p = 0.1
)
気になる方は見てみた方が良いと思うのですが、簡単に言うと、
AIが文章を生成する際には、サンプリングと言って「ある確率分布に従ってランダムに単語を選択する」らしいのですが、「Temperature」や「Top_p」はそのランダム性を制御するパラメータらしいです。 どちらも0以上の数値を入れ、その値によってランダム性が変わるっぽいです。
まず、Temperatureに関しては、「単語の出力確率を制御する」らしいです。 説明を見てもよく分からなかったので、ChatGPTさんに例を生成してもらうと、以下のように教えてもらえました。
例: temperature=0.1:
「質問: 人工知能とは何ですか?」
「答え: 人工知能(AI)は、機械に人間のような知的行動をさせる技術です。」
temperature=0.8:
「質問: 人工知能とは何ですか?」
「答え: AIは、データを使って自己学習することで、人間のような推論や予測を行う機械知能です。例えば、顔認識、音声アシスタントなどです。」
たしかに、temperature=0.8の方が文章に人間みというか、柔軟性がある感じがしますね。 このパラメータに関しては、今回の用途では必要がなさそうなので、0.1とかより低い数値でよさそうな気がします。
top_pに関しては、「出力の候補となる単語(トークン)の確率分布を制限する」らしいです。 要は、色々な単語に生成確率があったとして、何%以上の単語しか出力しませんよ的なやつだと思います。(違ったらすみません) 同様に、ChatGPTさんに例を生成してもらいました。
top_p=0.1:
「質問: 人工知能とは何ですか?」
「答え: 人工知能(AI)は、機械に人間のような知的行動をさせる技術です。」
top_p=0.8:
「質問: 人工知能とは何ですか?」
「答え: AIは、データを使って機械を学習させ、人間のような予測や行動を可能にする技術の総称です。」
数値が上がると語彙力が上がるイメージですかね。 こちらのパラメータに関しては、要約などをさせる上で、使われる単語にある程度柔軟性があったほうが良い気がするので、ある程度の数値が必要な気がします。
実装
実装はAPIにリクエストを送信レスポンスを出力するapp.py、PDFを処理するpdf_processor.pyに分けました。
app.py
# PDF内容の抽出 pdf_path = "pdfs/sample.pdf" pdf_content = extract_content_from_pdf(pdf_path) # 内容を分割 chunk_size = 10000 # 各チャンクのトークン数上限 chunks = [pdf_content[i:i + chunk_size] for i in range(0, len(pdf_content), chunk_size)] responses = [] # 各チャンクを送信 for i, chunk in enumerate(chunks): print(f"Sending chunk {i + 1}/{len(chunks)}") # 監視ログ用 response = client.chat.completions.create( model='Meta-Llama-3.1-405B-Instruct', messages=[ {"role": "system", "content": "あなたは決算報告書PDFの内容を分析する優秀な証券アナリストです。"}, {"role": "user", "content": chunk} ], temperature=0.1, top_p=0.8 ) responses.append(response.choices[0].message.content) # 応答を統合して送信 final_input = "\n\n".join(responses) print("Sending final summary request...") # 監視ログ用 final_response = client.chat.completions.create( model='Meta-Llama-3.1-405B-Instruct', messages=[ {"role": "system", "content": "あなたはすべての応答を統合し、要約、助言を行う優秀な証券アナリストです。出力は500文字程度の簡単な要約と、株価の上昇要因と下落要因を1〜5個まで挙げてください。"}, {"role": "user", "content": final_input} ], temperature=0.1, top_p=0.8 ) print("Final Response:") print(final_response.choices[0].message.content)
pdf_processor.py
import pdfplumber def extract_content_from_pdf(file_path): """ PDFファイルからテキストと表を抽出します。 """ all_content = [] with pdfplumber.open(file_path) as pdf: for page_number, page in enumerate(pdf.pages, start=1): text = page.extract_text() if text: all_content.append(f"--- Page {page_number} ---\n{text}") # テーブルの抽出 tables = page.extract_tables() for table_index, table in enumerate(tables): all_content.append(f"--- Table {table_index + 1} on Page {page_number} ---") for row in table: all_content.append("\t".join(row)) # 行をタブ区切りで結合 return "\n\n".join(all_content)
app.pyについては、見ればわかる通り、リクエストを送る際は複数に分けています。これは、API側で一回で送れるトークン数に限りがあるため、その制限を回避するために施しています。 pdf_processor.pyに関しては、この段階では別にapp.pyに入れちゃってもよかったのですが、今後複数のPDFを処理するなど、PDFの処理自体で色々改修する予定があるので分けてみました。
これらを踏まえて、とりあえず一回上記の内容でリクエストを送信してみました。
サンプルPDFには、トヨタの2025年3月期第2四半期の決算報告書PDFを用いました。
出力
トヨタ自動車株式会社の2025年3月期第2四半期(中間期)の業績分析
トヨタ自動車株式会社の2025年3月期第2四半期(中間期)の業績は、前年同期比で営業収益は増加したものの、営業利益と税引前利益は減少した。財政状態は前連結会計年度末比で総資産と負債が減少したものの、資本は増加しました。キャッシュ・フローの状況は、前中間連結会計期間比で営業活動によるキャッシュ・フローは減少したものの、投資活動によるキャッシュ・フローは増加しました。
株価の上昇要因
- 電気自動車への投資強化:トヨタ自動車は電気自動車への投資を強化しており、将来的にこの分野での成長が期待できます。
- 自動運転技術の開発:トヨタ自動車は自動運転技術の開発を進めており、この分野でのイノベーションが期待できます。
- コスト削減と効率化:トヨタ自動車はコスト削減と効率化を推進しており、これにより将来的に利益率の改善が期待できます。
株価の下落要因
- 世界的な自動車市場の動向:世界的な自動車市場の動向がトヨタ自動車の業績に影響を与える可能性があります。
- 為替変動:為替変動がトヨタ自動車の業績に影響を与える可能性があります。
- 競争の激化:自動車業界の競争が激化しており、トヨタ自動車の業績に影響を与える可能性があります。
結論
トヨタ自動車の2025年3月期第2四半期(中間期)の業績は、前年同期比で営業収益は増加したものの、営業利益と税引前利益は減少した。同社は電気自動車への投資強化、自動運転技術の開発、コスト削減と効率化を推進しており、将来的に成長が期待できます。しかし、世界的な自動車市場の動向、為替変動、競争の激化などの外部要因に影響を受ける可能性があります。
プロンプトの改善
出力された回答を見てみると、株価の上昇要因や、下落要因は「ほうほう」、となるものの、最初と最後の要約に関しては、どのくらい増加したなどの具体的な数値がなく、どんな決算なのかよくわかりません。 今回の目的は、「概要をぱっと見で把握できる」なので、もう少し決算の善し悪しのイメージを掴みやすくしたいです。 そこで、より分かりやすく、用途に沿った出力になるようにプロンプトを変えてみました。
改善したプロンプト
final_response = client.chat.completions.create(
model='Meta-Llama-3.1-405B-Instruct',
messages=[
{
"role": "system",
"content": """
あなたはすべての応答を統合し、要約、助言を行う優秀な証券アナリストです。出力は500文字程度の簡単な要約と、以下の要件を厳密に遵守してください。
【絶対遵守事項】
1. 「前年比」「前期比」「前年同期比」などの比較対象期間を区別し、原文にある通りに正確に記載すること。
2. 指定フォーマットで回答すること。以下のフォーマットに厳密に従うこと。
- 売上高:〇〇円(前年同期比〇〇%増加 or 減少)
- 利益(営業利益):〇〇円(前年同期比〇〇%増加 or 減少)
- 資産:〇〇円(前期末比〇〇%増加 or 減少)
- キャッシュフロー:営業キャッシュフロー:〇〇円(前年同期比〇〇%増加 or 減少)
- 株価上昇要因:
- 株価下落要因:
3. 必ず原文データに基づき、記載した数値を再確認すること。
4. 回答は日本語で行うこと。
5. 株価上昇/下落要因は、レポートや抽出データから考えられる範囲で合理的な理由を1〜5個程度挙げること。
【タスク】
- 以下のPDF(またはテキスト)から売上高や利益などの数値を抽出し、比較対象と増減率を明確に示した上で指定のフォーマットで回答する。
- 最終出力時には、分析対象となる全メッセージ(PDFデータ断片)を統合した上で要約を作成し、株価変動要因も列挙する。
以上の指示に従って回答してください。
"""
},
{
"role": "user",
"content": f"以下は、決算報告書抜粋データです。これを基に上記の指示に従って出力してください。{final_input}"
}
],
temperature=0.1,
top_p=0.8
)
改善後の回答
トヨタ自動車株式会社の2025年3月期第2四半期(中間期)決算要約
- 売上高:23兆2824億円(前年同期比5.9%増加)
- 利益(営業利益):2兆4642億円(前年同期比3.7%減少)
- 資産:89兆1692億円(前期末比1.0%減少)
- キャッシュフロー:営業キャッシュフロー:1兆8171億円(前年同期比4,609億円減少)
株価上昇要因:
- 為替変動の影響による利益増加
- 原価改善の努力による利益増加
- 金融事業の利益増加
- 営業利益の減少幅が予想より小さかったこと
- 自動車セグメントの販売台数が増加したこと
株価下落要因:
- 販売台数の減少による利益減少
- 諸経費の増加による利益減少
- 日野自動車㈱による認証不正問題の影響による利益減少
- 営業利益が前年同期比で減少したこと
- 為替差損益が減少したこと
改善後の株価上昇(下落)要因、は少し簡素になってしまいましたが、決算要約に関しては把握しやすくなったと思います。 株価上昇(下落)要因については、改善前の回答も悪くなかったので、より柔軟性のある回答が出るように調整が必要な気がします。(今後の展望)
まとめ
今回は、文章生成AIをAPI経由で利用し、プロンプトを用いて自分の用途に沿った出力を得られるようにしました。 普段からChatGPTなど、生成AI自体はよく使ってるのですが、今回「生成AIの出力を制御する」ということを初めて行ってみて、「意外と難しいし、奥が深い」と感じました。
生成AIを今までは検索エンジン的な活用や簡易なタスク処理に使う「便利屋さん」的な用途でしか使ってなかったのですが、「これからは本格的なツールとして使われていくだろう」という手応えを得ました。そして、その際きちんと"ツール"として使われるために、適切に出力を制御するための「プロンプトエンジニアリング」の重要性を感じました。これまでは「プロンプトエンジニアリングなんて自分にはまだ必要なさそうだな。」と思っていましたが、これからはX(旧Twitter)などでプロンプト例が流れてきたら一読してみようと思いました。また、「ここにもAIを活用できるのでは」という想像力もなんとなくついた気がします。
今回ちょっと作ってみただけでも、このような感想を抱けたので、もしまだこのような「ツールとしてAIを使う」体験をしていない方は、是非一度なにか作ってみてはいかがでしょうか。
テコテックの採用活動について
テコテックでは新卒採用、中途採用共に積極的に募集をしています。
採用サイトにて会社の雰囲気や福利厚生、募集内容をご確認いただけます。
ご興味を持っていただけましたら是非ご覧ください。
tecotec.co.jp